2.1.1. Процесс кодирования — декодирования информации
Процесс коммуникации легче всего представить в ее наиболее простой форме, то есть как сообщение и передачу определенных данных. Но любая информация передается с помощью той или иной системы знаков. Для этого необходимы отправитель, получатель, инстанция посредничества. Отправитель зашифровывает свою информацию с помощью кода или знаковой системы. Взаимопонимание между партнерами по коммуникации в этом случае может быть достигнуто только тогда, когда между ними заранее было установлено содержание и значение используемых кодов и знаков. Успех коммуникации достигается лишь в том случае, если участники коммуникации обладают общей возможностью интерпретации определенного знака. Эти процессы являются важнейшими элементами коммуникативного акта. Поскольку человек не владеет телепатией и не способен передать электрические импульсы непосредственно из своего мозга в мозг партнера, то возникает необходимость зашифровать свои мысли, чтобы потом передать их вербально или невербально. При межкультурной коммуникации каждая культура представляет собой систему кодов, которая распространяет свое действие на повседневные отношения, социальные и культурные нормы и т.д. Эти кодовые системы культур, как правило, несопоставимы между собой или в лучшем случае сопоставимы только ограниченно. В связи с этим в процессе коммуникации приобретает важное значение проблема кодирования и декодирования информации.
Кодирование — это процесс зашифровки наших мыслей, чувств, эмоций в форму, узнаваемую другими. Для этого человек использует символы, которые могут быть письменными, вербальными, невербальными, математическими, музыкальными и т.д. Набор таких символов является сообщением.
Декодирование — это процесс получения и интерпретации сообщений, получаемых человеком извне. Он связан с расшифровкой символов, составляющих сообщение.
Способы кодирования и декодирования сообщений формируются под влиянием опыта человека, который понимается не только как индивидуальный опыт, но и как опыт группы, к которой принадлежит человек, а также опыт той культуры, представителем которой этот человек является, осваивает ее в процессе инкультурации.
2.1.2. Символический характер коммуникации
Необходимость в согласованном поведении людей, закреплении и сохранении полученных знаний, их передаче от поколения к поколению привела к возникновению различного рода символов. Символ — одно из самых многозначных понятий в культуре. Изначальный смысл этого слова означал удостоверение личности, которым служил simbolon — половинка черепка, бывшая гостевой табличкой. Символ в культуре — универсальная категория, с помощью которой люди могут выразить и передать все свои внутренние состояния. Процесс общения в этом отношении можно рассматривать как обмен символами, с помощью которых происходит передача нужной информации. Символы — это условные знаки, обозначающие какие-то предметы, явления или процессы. Главная их особенность заключается в способности «замещать» реальные предметы или явления и выражать заключенную в них информацию. Чаще всего мы имеем дело с символами-словами, хотя есть символы-предметы, процессы и пр.
В той или иной культуре символы могут принимать различные виды. В качестве символов используются слова, невербальные приемы (пожатия рук, поклоны, приветствия), материальные предметы. Так, например, государственный флаг символизирует принадлежность соответствующей территории к данному государству или служит выражением лояльности гражданина к своему государству. Кроме того, в качестве религиозных символов используются крест, полумесяц, шестиконечная звезда и т.д. Благодаря портативности символов появляется возможность передавать от поколения к поколению огромное количество знаний и информации. Книги, картины, фильмы, видеозаписи, компьютерные диски помогают культуре сохранить все, что может быть полезным для последующих поколений.
Любая культура создает свою собственную систему символов и придает каждому символу соответствующие значения. Но культуры не только наполняют свои символы разным значением, но и используют символы в разных целях. Поэтому в процессе коммуникации всегда важно помнить, что символы являются таковыми только потому, что определенная группа людей соглашается принять их как символы. Между символом и его значением зачастую нет естественной связи. Их отношения произвольны и варьируются в разных культурах. Поэтому человеку, незнакомому с символикой флага, он будет представляться всего лишь куском ткани, прикрепленным к палке. Но даже в рамках одной культуры расшифровка символа будет варьироваться в зависимости от опыта человека и от конкретной жизненной ситуации, в которой он находится при этом. Раскрытие значения символов происходит в форме их денотации и коннотации.
Так, лиса — род млекопитающих семейства псовых. Это — денотация символа. Но для большинства говорящих на русском языке это слово еще ассоциируется с хитростью и изворотливостью. Это — коннотация символа.
Как слова, так и символы-вещи могут менять свои значения — от поколения к поколению, от региона к региону. Об этом также необходимо постоянно помнить в процессе коммуникации.
studfiles.net
Процесс кодирования — Энциклопедия по экономике
ШУМ. Обратная связь заметно повышает шансы на эффективный обмен информацией, позволяя обеим сторонам подавлять шум. На языке теории передачи информации шумом называют то, что искажает смысл. Источники шума, которые могут создавать преграды на пути обмена информацией, варьируют от языка (в вербальном или невербальном оформлении) до различий в восприятии, из-за которых может изменяться смысл в процессах кодирования и декодирования, и до различий в организационном статусе между руководителем и подчиненным, которые могут затруднять точную передачу информации. [c.175]Напрягите свое воображение и вскоре убедитесь, что процесс кодирования станет [c.40]
По своим свойствам информационная экономика носит глобальный характер и является основой формирования и развития информационного общества. В условиях информационного общества процессы кодирования и декодирования научно-экономической информации достигают такого уровня, при котором наблюдается ежегодное удвоение объема знаний. В этой связи для того чтобы успеть усвоить нарастающий объем информации и не отстать от темпов современной научно-технологической и экономической жизни, индивиду, специалисту и персоналу необходима возможность непрерывного обновления своих знаний. Такая возможность превращается в реальность, если проведены в жизнь основные принципы информатизации, имеется достаточно высокая информационная культура и развитый разветвленный рынок информационных услуг. [c.15]
На этой стадии отправитель должен произвести некоторую оценку. Предположение относительно восприятия сообщения получателем определит и способ кодирования, и способ передачи (выбор канала передачи информации), и способ получения информации (процесс декодирования получателем). Отправителю следует решить, как будет выглядеть его сообщение будет ли оно детализировано или обобщено, представлено в стиле теории икс или в стиле теории игрек , будет ли оно содержать примеры и метафоры, а также каков будет его тон — строгим или с юмором, и используемые термины — профессиональный жаргон или обычный язык. Если вы не отнесетесь к процессу кодирования с достаточным вниманием, если вы не разработаете его всесторонне, то информационный обмен может и не произойти. [c.275]
Получатель — это человек, которому предназначено сообщение. Сообщение должно попасть непосредственно получателю, хотя на практике зачастую происходит по-другому. Если, например, в сообщении указывается характер обязательных для супервайзера действий, то получателем сообщения должен быть именно он, а не менеджер отдела. Это сообщение, скорее всего, пройдет через руки менеджера отдела, но выбор канала передачи и процесс кодирования должны ориентироваться именно на супервайзера, а не на менеджера. [c.276]
Процесс кодирования Канал пере/ щчи я Получатель [c.277]
Отправитель должен оценить содержание сообщения, выбранный канал передачи и процесс кодирования с учетом требования столь же высокой значимости его собственных целей, содержащихся в сообщении, как и в списке приоритетов получателя. В данном случае оценка зависит исключительно от личного мнения отправителя, и его роль в успешном коммуникационном процессе весьма велика. Процесс должен контролироваться отправителем и далее нужно будет оценивать информацию, поступившую по каналу обратной связи и каналу подтверждения принятия обязательств. Если вдруг отправителю не удается поместить цель информационного обмена на верхние строки в списке приоритетов получателя, коммуникационная программа может вообще не дать ожидаемых результатов. [c.280]
Внимательно присмотритесь к перечисленным двенадцати элементам. Все они, за исключением процесса декодирования, находятся под контролем отправителя. Если в результате вам не удалось установить достаточно надежной связи с получателем, то это произошло из-за ошибок при выборе канала передачи, в процессе кодирования или составления самого сообщения, выборе канала обратной связи и других элементов, необходимых для корректного обмена информацией. [c.281]
Важным примером вспомогательной К. является случай, когда каждый предмет образует свой собственный класс. Такая К. называется кодированием. Процесс кодирования (например, по принципу один символ — один байт , применяемому в компьютерах фирмы IBM) позволяет формализовать процесс обработки информации, оставляя за человеком возможность неформальной трактовки его результата. Хотя коды для объектов выбираются произвольно, в [c.113]
В модели выделены ключевые факторы эффективных коммуникаций. Отправители должны определить целевую аудиторию для своих обращений и желаемый отклик на них. В процессе кодирования сообщения необходимо заранее представить себе его возможное восприятие и декодирование целевой аудиторией. Для этого отправители должны использовать эффективные медиа (средства рекламы), охватывающие целевую аудиторию, и предложить каналы обратной связи для проверки ее отклика. [c.559]
Процесс кодирования заключается в вырезке на перфокартах отверстий. Каждому признаку соответствует определенный вырез до края перфокарты (глубокий или мелкий). Отсутствие вырезки означает, что сведения не закодированы. Перфокарты с вырезами, которым соответствует определенное понятие, считаются закодированными и помещаются в массив картотеки. [c.94]
Существует и еще один подход, при котором отладка частично пересекается с написанием программ. Некоторые программисты предпочитают написать несколько строк кодов и тут же проверить их работу. Этот подход позволяет отыскать ошибки кодирования непосредственно в процессе кодирования. Достоинством такого подхода является и то, что программа свежа в памяти, что позволяет легче выявить ошибки. [c.171]
Кодирование является одним из основных элементов системы автоматизированного нормирования, при помощи которого обеспечивается ввод в ЭВМ исходной информации, а также обратное преобразование закодированной информации о результатах расчета в общепринятые или близкие к ним формы технической документации. Процесс кодирования состоит в том, что, пользуясь определенными правилами, объектам кодирования присваивают условные обозначения — коды, которые представляют собой расположенные в определенном порядке группы букв и цифр. Совокупность правил присвоения кодов объектам является системой кодирования. [c.313]
Данная система кодирования содержит только ту информацию, которая необходима для совершенно конкретных целей технологического проектирования. Поэтому в ряде случаев объектом кодирования являются не деталь или машина, а некоторая конструкторская или технологическая модель детали или машины, их абстрактная схема. Это способствует уменьшению объема информации и упрощению процесса кодирования сложных деталей и машин. [c.40]
Обычно источник имеет представление о том, как бы он хотел, чтобы сообщение интерпретировалось получателем/Достижение определенного результата интерпретации, т.е. толкования сообщения получателем, предполагает должное кодирование идеи сообщения. Процесс кодирования в значительной степени субъективен, поскольку зависит от личности кодирующего, от располагаемого им спектра возможностей кодирования. Кроме того, возможности выбора кодов, знаковых систем зависят от конкретного канала, или средства передачи сообщения — телевидения, Интернет, радио, газеты. [c.90]
Формы записи результатов наблюдения (формы наблюдения) составлять намного проще, чем анкеты. Исследователю не нужно принимать во внимание психологическое влияние вопросов и то, как они будут заданы. Ему необходимо только разработать форму, которая четко определяет необходимую чтобы полевой работник мог точно ее записать, а также упрощает процесс кодирования, учета и анализа данных, [c.395]
Информационный процесс кодирования информации встречается в нашей жизни на каждом шагу. Любое общение между людьми происходит именно благодаря тому, что они научились выражать свои образы, чувства и эмоции с помощью специально предназначенных для этого знаков — звуков, жестов, [c.15]
Отправитель-сторона, посылающая обращение другой стороне. Кодирование-процесс представления мысли в символической форме. [c.484]
При подготовке конкретных маркетинговых коммуникаций коммуникатору необходимо уметь разбираться в девяти составляющих любого коммуникационного процесса, которыми являются отправитель, получатель, кодирование, расшифровка, обращение, средства распространения информации, ответная реакция, обратная связь и помехи. Первейшая задача коммуникатора заключается в выявлении целевой аудитории и ее характеристик. Затем ему предстоит определить желаемую ответную реакцию, будь то осведомленность, знание, благорасположение, предпочтение, убежденность или совершение покупки. После этого необходимо разработать обращение с эффективным содержанием, эффективной структурой и эффективной формой. Далее нужно выбрать средства распространения информации для проведения как личной, так и неличной коммуникации. Обращение должно быть доведено до получателя лицом, заслуживающим доверия, а именно кем-то, кому присущи профессионализм, добросовестность и привлекательность. И наконец, коммуникатор должен постоянно следить за ростом осведомленности рынка, ростом числа опробовавших товар и численностью тех, кто остался доволен товаром в процессе опробования. [c.506]
Кодирование-в коммуникации процесс представления мысли в символической форме. [c.507]
Этапы процесса — разработка идеи, кодирование л выбор канала, передача и расшифровка. [c.189]
Электронные информационные технологии не только вдыхают жизнь в существующие отрасли, но и рождают новые. Хорошим примером может служить связанная с высокими рисками сфера генетических исследований, где компаниям приходится годами вкладывать огромные ресурсы без какой бы то ни было гарантии успеха. В таких областях, оперирующих исключительно знаниями, переход на электронные информационные потоки может означать удвоение темпов исследований и повышение шансов на успех. Предметом генетических исследований является молекула ДНК, которую часто называют строительным кирпичиком биологической жизни. ДНК содержит гены, управляющие всеми клеточными процессами, такими,, как усвоение питательных веществ, клеточное дыхание, построение различных элементов и структур живой клетки. В процессе генетического кодирования гены управляют типом и количеством синтезируемых белков белки же непосредственно реализуют все химические процессы внутри клетки. Если ДНК будет повреждена или подвергнется мутации, ее управляющие инструкции могут оказаться неверны в результате вместо нужных белков начнут синтезироваться их измененные формы или изменится объем производства — нарушится химический баланс клетки. А когда на клеточном уровне развиваются такие процессы, организм в целом заболевает или даже умирает. [c.279]
При переходе от ручных документов к машиночитаемым усложняется процесс фиксации информации на носителях, появляется необходимость кодирования, позволяющего представить информацию в сжатом виде, пригодном для дальнейшей обработки. Средством, обеспечивающим возможность перехода к кодированию, служит информационный язык, включающий совокупность условных знаков (обозначающих определенные понятия) и совокупность правил (грамматику) построения высказываний. [c.300]
Второй возможный путь решения проблемы — глобальный, высоко капиталоемкий, но обладающий чрезвычайной эффективностью. Он состоит в полной автоматизации учетного процесса с использованием электронных сетей, что предполагает как формирование товарных и кассовых отчетов непосредственно в аптеках с передачей информации в центральный офис, так и формирование системы штрихового кодирования, позволяющей вести количественный учет товаропотока. [c.428]
Для съема показаний и обработки диаграмм многих показывающих и самопишущих приборов нужен большой штат обслуживающего персонала. Если учесть возможные ошибки операторов при считывании показаний, обработке с целью масштабирования результатов и приведении их к единицам измеряемых величин, следует признать, что наиболее удобная форма представления информации — цифровая. Она легко поддается кодированию, а в закодированном виде данные о процессе могут поступать в ЭВМ для дальнейшей обработки. [c.210]
Однако такая форма не получила широкого распространения из-за необходимости больших затрат для ее внедрения огромных размеров счетно-перфорационных машин и многочисленности их необходимого комплекта сложности и громоздкости технологических процессов учета (шифровка и кодирование документов, обработка документов, перфорация и ее контроль, сортировка массива перфокарт, табуляция, контроль и выпуск отчетных табуляграмм и др.). [c.183]
Кроме того, информация может содержать количественные и качественные показатели. При необходимости ее дальнейшей, особенно математической, обработки последние неприемлемы и требуют применения систем кодирования в балльные и иные измерители свойств предметов, объектов, процессов. [c.223]
Результативность управления предприятием в значительной степени определяется уровнем организации процесса управления и качеством его информационного обеспечения. В широком смысле под информационным обеспечением хозяйственной деятельности понимается совокупность информационных ресурсов и способов их организации. Основными элементами информационного обеспечения являются система документации и документооборота система классификации и кодирования информационная база (картотеки, классификаторы, массивы нормативно-справочной, текущей информации, накопительные массивы и т. д.) документы регулятивного характера (должностные и технологические инструкции, обеспечивающие организацию документооборота и ведение информационной базы). [c.212]
Многие экономисты предлагают формировать показатели синтетического учета путем последовательного агрегирования и подсчета данных аналитического учета, поскольку и те, и другие формируются на основе единого массива первичных данных. Другие считают, что формирование данных синтетического и аналитического учета должно осуществляться параллельно. При этом возможность разночтений и неточностей исключается, так как информация обоих видов учета основана на единых первичных данных. Однако в первом случае неоправданно ограничивается аналитический учет только одной системой группировки, выбранной в процессе агрегирования данных синтетического учета, во втором — возникает возможность создавать столько систем аналитических счетов, сколько определяют интересы контроля и управления и позволяет система кодирования. [c.362]
В условиях организации АРМ применяется один из вариантов автоматизированной формы учета. Поэтому в АРМ бухгалтера получают дальнейшее развитие и совершенствование основные элементы автоматизированной формы бухгалтерского учета. В частности, организация АРМ бухгалтера меняет технологический процесс обработки учетной информации отпадает необходимость в применении кодов учетных номенклатур кодированию подвергаются только те показатели, по которым предусматривается обобщение данных и получение итогов раз- [c.229]
Приступая к составлению классификаторов, прежде всего следует выяснить, какие общегосударственные и отраслевые классификаторы можно использовать при решении данной задачи, и только затем приступают к составлению локальных кодов. Классификаторы приобретают особое значение в компьютерных информационных системах, предусматривающих создание автоматизированных рабочих мест (АРМ). Кодированию в документах подлежат те признаки, по которым выполняется группировка информации в машине. Разработка кодов осуществляется при составлении техно-рабочего проекта. Наряду со специалистами по машинной обработке в этом процессе заметную роль играют экономисты-пользователи. [c.100]
После составления классификации выполняется следующий этап — кодирование — процесс присвоения условного обозначения различным позициям номенклатуры. Код — условное обозначение объекта знаком или группой знаков по определенным правилам, установленным системой кодирования. Коды могут быть цифровыми, буквенными, буквенно-цифровыми и состоять из одного или нескольких знаков. При машинной обработке предпочтение отдается [c.100]
Типовая технология использования системы штрихового кодирования в России магазинами типа супермаркет рассматривается на примере процесса оформления поступления товаров и его продажи покупателям. [c.115]
Применение штрихового кодирования значительно ускоряет процесс ввода данных в машину. Этот метод находит все большее применение при учете типовых операций. [c.159]
Когда приемник видит или слышит сообщение, он декодирует его. Это процесс, с помощью которого приемник интерпретирует символы, переданные источником. Задача состоит в том, чтобы декодирование, выполненное приемником, соответствовало процессу кодирования в источнике. Следовательно, приемник интерпретирует сообщение именно так, как предполагается источником. Возможно, что цель рекламы Marlboro состоит в том, чтобы ассоциировать данную торговую марку с образом мужественного ковбоя. Если именно таким образом будет декодировано это сообщение, то цель данной коммуникации достигнута. Однако, некурящий человек может интерпретировать эту рекламу совершенно по-другому, отвергая указанную ассоциацию и заменяя ее на риск для здоровья. Сообщения, акцент в которых делается не на изображение, а на текст, также можно декодировать по- [c.323]
Система кодирования определяет характеристику минимума первичных данных, накапливаемых в системе ЭВМ, и порядок обработки информации, прежде всего порядок совмещения данных аналитического и синтетического учета, установления связи между ними. Как же строить кодирование хозяйственной операции по принципу счетной формулы (В. II. Подольский) или ввести код хозяйственной операции, по которому корреспонденция счетог. будет определена в ЭВМ на основе классификатора корреспонденции хозяйственных операций (С. И. Волков, Ю. П. Максимов, Н. В. Лапухин). Отражение счетной формулы в процессе кодирования трудоемко, но повышает роль бухгалтера в процессе контроля первичной информации. Создание классификатора хозяйственных операций требует большой и кропотливой подготовительной работы и не может обеспечить перечисление всех возможных вариантов корреспонденции счетов, которые могут возникнуть в процессе хозяйственной деятельности. Поэтому форма бухгалтерского учета на ЭВМ должна предусматривать оба способа кодирования данных. Для массовых хозяйственных операций, данные о которых вводятся в ЭВМ преимущественно при помощи автоматических датчиков, необходимо предусматривать автоматизацию определения корреспонденции счетов. Для хозяйственных операций, которые предварительно оформляются бухгалтерскими документами, система кодирования должна предусматривать определение счетной формулы бухгалтером, проводящим предварительный контроль и обработку таких документов. [c.248]
В книге приведенд обоснование 17 факторов производительности труда и предложена схема их классификации, согласующаяся с межотраслевой классификацией Госплана СССР. По каждому фактору предложены конкретные показатели, их характеризующие, разработана система кодирования факторов для использований в АСУ—нефть . В результате проведенных исследований установлено, что все многообразие известных в настоящее в,ремя факторов производительности труда характеризуется бйлее чем 60 количественными и 5 качественными показателями, диапазон колебания которых весьма значителен. ( Природные условия разработки нефтяных месторождений, характеризуются большой пестротой параметров, которые во многом определяют значительные различия (почти в 650 раз по анализируемым НГДУ) уровней производительности труда. В процессе эксплуатации нефтяные месторождения проходят четыре стадии разработки, вследствие этого с каждым годом все больше месторождений вступает в поздние стадии разработки, когда дебиты скважин по нефти и объем добычи нефти резко снижаются, а процесс добычи нефти непрерывно усложняется. [c.183]
Опыт, накопленный в области моделирования нефтеперерабатывающего предприятия, показывает, что проведение таких этапов, как формирование матрицы коэффициентов, кодирование ин- формации, перевод информации на машинные носители, связано с трудоемким процессом проверки и исправления ошибок. Поэтому наиболее рациональной представляется такая организация процесса моделирования, при которой без дополнительной ручной обработки первичные носители информации сразу переносились бы на машинные носители, а формирование матрицы козффициен-тоа модели линейного программирования осуществлялось бы с помощью ЭВМ в готовом для решения виде. [c.168]
Создание рационального потока информации должно опираться на определенные принципы. Таковыми являются выявление информационных потребностей и способов наиболее эффективного их удовлетворения объективность отражения процессов производства, обращения, распределения и потребления, использования природных, трудовых, материальных и финансовых ресурсов единство информации, поступающей из различных источников (бухгалтерского, статистического и оперативного учета), а также плановых данных, устранение дублирования в первичной информации оперативность информации, обеспечивающаяся применением новейших средств связи и внедрением методов дистанционной передачи первичных данных непосредственно на воспринимающие устройства ЭВМ всесторонняя разработка первичной информации на ЭВМ с выведением на ее основе необходимых производных показателей возможное ограничение объема первичной информации и повышение коэффициента ее использования кодирование первичных данных с целью эффективного использования каналов связи и преобразующих устройств разработка программ использования и анализа первичной информации для целей планирования и управления.1 [c.61]
Необходимо обратить внимание на то, что в ОКДП использована комбинированная (иерархически-фасетная) классификационная структура. Кодирование разделов, подразделов, групп и подгрупп видов экономической деятельности, а также классов и подклассов продукции и услуг осуществляется по иерархической схеме, а видов продукции и услуг — по фасетной схеме. Применение комбинированной схемы позволяет при формировании Классификатора более полно использовать все отведенное в пределах семи разрядов кодовое пространство. Такая схема обеспечивает большую устойчивость структуры ОКДП в процессе его ведения, так как основные изменения происходят на уровне видов продукции и услуг и не затрагивают, как правило, группировки более высокого уровня. Сами же фасеты в большинстве случаев строятся по иерархическому принципу с введением головной позиции в список до десяти наименований, которая индексируется кодом с цифрой О в последнем разряде. Для индексирования кодовой позиции со словами прочая , прочее , прочие , прочий используется цифра 9 в последнем разряде. [c.81]
Основная цель ASE-технологии состоит в том, чтобы отделить проектирование АИС и АИТ от ее кодирования и последующих этапов разработки, а также максимально автоматизировать процессы разработки и функционирования систем. [c.75]
economy-ru.info
2.1.1. Процесс кодирования — декодирования информации
Процесс коммуникации легче всего представить в ее наиболее простой форме, то есть как сообщение и передачу определенных данных. Но любая информация передается с помощью той или иной системы знаков. Для этого необходимы отправитель, получатель, инстанция посредничества. Отправитель зашифровывает свою информацию с помощью кода или знаковой системы. Взаимопонимание между партнерами по коммуникации в этом случае может быть достигнуто только тогда, когда между ними заранее было установлено содержание и значение используемых кодов и знаков. Успех коммуникации достигается лишь в том случае, если участники коммуникации обладают общей возможностью интерпретации определенного знака. Эти процессы являются важнейшими элементами коммуникативного акта. Поскольку человек не владеет телепатией и не способен передать электрические импульсы непосредственно из своего мозга в мозг партнера, то возникает необходимость зашифровать свои мысли, чтобы потом передать их вербально или невербально. При межкультурной коммуникации каждая культура представляет собой систему кодов, которая распространяет свое действие на повседневные отношения, социальные и культурные нормы и т.д. Эти кодовые системы культур, как правило, несопоставимы между собой или в лучшем случае сопоставимы только ограниченно. В связи с этим в процессе коммуникации приобретает важное значение проблема кодирования и декодирования информации.
Кодирование — это процесс зашифровки наших мыслей, чувств, эмоций в форму, узнаваемую другими. Для этого человек использует символы, которые могут быть письменными, вербальными, невербальными, математическими, музыкальными и т.д. Набор таких символов является сообщением.
Декодирование — это процесс получения и интерпретации сообщений, получаемых человеком извне. Он связан с расшифровкой символов, составляющих сообщение.
Способы кодирования и декодирования сообщений формируются под влиянием опыта человека, который понимается не только как индивидуальный опыт, но и как опыт группы, к которой принадлежит человек, а также опыт той культуры, представителем которой этот человек является, осваивает ее в процессе инкультурации.
2.1.2. Символический характер коммуникации
Необходимость в согласованном поведении людей, закреплении и сохранении полученных знаний, их передаче от поколения к поколению привела к возникновению различного рода символов. Символ — одно из самых многозначных понятий в культуре. Изначальный смысл этого слова означал удостоверение личности, которым служил simbolon — половинка черепка, бывшая гостевой табличкой. Символ в культуре — универсальная категория, с помощью которой люди могут выразить и передать все свои внутренние состояния. Процесс общения в этом отношении можно рассматривать как обмен символами, с помощью которых происходит передача нужной информации. Символы — это условные знаки, обозначающие какие-то предметы, явления или процессы. Главная их особенность заключается в способности «замещать» реальные предметы или явления и выражать заключенную в них информацию. Чаще всего мы имеем дело с символами-словами, хотя есть символы-предметы, процессы и пр.
В той или иной культуре символы могут принимать различные виды. В качестве символов используются слова, невербальные приемы (пожатия рук, поклоны, приветствия), материальные предметы. Так, например, государственный флаг символизирует принадлежность соответствующей территории к данному государству или служит выражением лояльности гражданина к своему государству. Кроме того, в качестве религиозных символов используются крест, полумесяц, шестиконечная звезда и т.д. Благодаря портативности символов появляется возможность передавать от поколения к поколению огромное количество знаний и информации. Книги, картины, фильмы, видеозаписи, компьютерные диски помогают культуре сохранить все, что может быть полезным для последующих поколений.
Любая культура создает свою собственную систему символов и придает каждому символу соответствующие значения. Но культуры не только наполняют свои символы разным значением, но и используют символы в разных целях. Поэтому в процессе коммуникации всегда важно помнить, что символы являются таковыми только потому, что определенная группа людей соглашается принять их как символы. Между символом и его значением зачастую нет естественной связи. Их отношения произвольны и варьируются в разных культурах. Поэтому человеку, незнакомому с символикой флага, он будет представляться всего лишь куском ткани, прикрепленным к палке. Но даже в рамках одной культуры расшифровка символа будет варьироваться в зависимости от опыта человека и от конкретной жизненной ситуации, в которой он находится при этом. Раскрытие значения символов происходит в форме их денотации и коннотации.
Денотация — это значение символа, признаваемое большинством людей в данной культуре. Коннотация —вторичные ассоциации, разделяемые лишь несколькими членами данного сообщества. В силу этого они всегда субъективны и эмоциональны по своей природе.
Так, лиса — род млекопитающих семейства псовых. Это — денотация символа. Но для большинства говорящих на русском языке это слово еще ассоциируется с хитростью и изворотливостью. Это — коннотация символа.
Как слова, так и символы-вещи могут менять свои значения — от поколения к поколению, от региона к региону. Об этом также необходимо постоянно помнить в процессе коммуникации.
studfiles.net
Процесс кодирования.
Процесс кодирования информации может производиться либо ручным , либо автоматическим способом. При ручном, неавтоматическом способе кодирования вручную отыскивается нужный код в предварительно составленном каталоге кодов и записывается в документе в виде цифровых или алфавитно-цифровых символов.
При автоматическом способе кодирования человек производит запись на естественном языке в виде слов, цифр и общепринятых обозначений в документе, который читается специальным автоматом. Этот автомат предварительно кодирует документ и записывает все данные в двоичном коде.
Ввод информации в ЭВМ в виде буквенно-цифрового текста на естественном языке и кодировании в машине требует хранения в памяти ЭВМ словаря, в котором каждому слову соответствует определенный код. По этому словарю машина сама кодирует текст. При этом отпадает необходимость в классификации и кодировании информации по ее смысловому содержанию, так как кодируются сами слова, выражающие определенные характеристики предметов.
Большое разнообразие технических характеристик и других данных, относящихся к производству и потреблению многочисленных видов продукции, не позволяет включить все необходимые данные для их производства в код продукции, так как этот код содержал бы большое число символов.
Поэтому задача кодирования продукции заключается в том, чтобы иметь возможно более короткий код, по которому в памяти машины можно было бы найти подробную информацию о всех необходимых данных, относящихся к каждому изделию. Таким кодом является ключевой код. Для каждого ключевого кода в памяти ЭВМ должен храниться массив данных, которые извлекаются из памяти и используются для решения различных задач. Этот массив информации должен быть единым для всех решаемых задач, например каталогом продукции, где в одном месте хранятся все необходимые данные о каждом предмете. Разделение его на ряд отдельных массивов, записанных, например, на различных участках магнитной ленты, нецелесообразно, так как это привело бы к повторению одной и той же информации и увеличению объема хранимой информации.
Основное требование к ключевому коду — однозначный поиск ЭВМ признаков, относящихся к данному предмету, для которого ключевой код является адресом.
Ключевой код может быть просто порядковым регистрационным номером и не нести какой-либо конкретной информации о продукции или, наоборот, может быть построен по определенной системе классификации и содержать конкретную информацию об основных признаках продукции, вполне ее определяющих.
Второй способ кодирования более эффективен, так как регистрационный код не дает возможности осуществить предварительную сортировку информации по ее содержанию.
Ключевой код позволяет производить сортировку карточек продукции по главным определяющим признакам. Детальная спецификация и ее остальные характеристики находятся в предварительно отсортированных карточках.
Виды кодов.
Код, символы которого соответствуют определенным предметам или характеристикам, называется прямым кодом. Если код непосредственно не содержит информацию о предмете или его признаках, а представляет адрес, указывающий местоположение информации, где содержится необходимые сведения, то он называетсяадресным кодом. Адресный код применяется для сокращения кода и быстрого поиска больших массивов информации.
За единицу количества информации принимается 1 бит, т.е. один двоичный разряд (0 или 1). Буквы, десятичные цифры и другие символы внутри ЭВМ представляются в виде групп двоичных разрядов. Операция представления их в таком виде называется двоичным кодированием. Группа из n двоичных чисел позволяет закодировать 2n различных символов. Такая группа называетсябайтом.
Более крупной единицей информацией является машинное слово, представляющее собой последовательность символов, занимающих одну ячейку в памяти машины. В зависимости от ЭВМ машинного слова может колебаться в пределах— от 16 до 64 двоичных разрядов. машинное слово может быть командой, числом или буквенно-цифровой последовательностью. Обычно машинное слово используется как единое целое в ЭВМ, хотя на некоторых машинах допускается обработка частей машинного слова.
Массив информации, содержащий 1024 машинных слова , называется страницей. Каждый отдельный блок памяти содержит обычно 16 и более страниц. Местоположение (адрес) слова в памяти определяется кодом адреса, содержащим номер блока , страницы и номера слова в этой странице.
Для упорядочения информации о множестве объектов, а также для облегчения их поиска и сортировки по заданным признакам или характеристикам применяется классификация этого множества. Классификация—это условное разбиение множества на ряд классов, подклассов и других группировок по принятой системе счисления и по заданным признакам и характеристикам.Классификационный код—это такой код , в котором отдельными символами или группой символов представлен каждый из классифицируемых признаков или каждая конкретная характеристика предмета.
Структура и число символов классификационного кода целиком определяется принятой классификацией множества , которая , в свою очередь , зависит от поставленных целей и задач. В классификационном коде каждый символ заключает в себе определенную информацию о конкретном признаке или характеристике предмета. В отличии от этого порядковый ,илирегистрационный код, содержащий присвоенный данному предмету порядковый номер при его регистрации без учета его признаков и характеристик , может служить только адресом для поиска местоположения информации о данном предмете. Во многих случаях применяются смешанные коды , в которых имеется как классификационная часть , так и порядковые номера для списка классифицируемых предметов множества.
studfiles.net
Кодирование и декодирование информации: что это такое
Рассмотрим детальнее, что такое кодирование сообщений, а также декодирование информации.
Для передачи информации люди используют естественные языки.
В повседневной жизни мы общаемся с помощью неформальной речи, а в деловой сфере используем формальный язык.
Сегодня для передачи и отображения информации мы используем вычислительную технику, которая «не понимает» наш язык без специальных операций – кодирования и декодирования.
Рассмотрим эти понятия детальнее, а также все виды и наглядные примеры кодирования/декодирования.

Cодержание:
Базовые понятия
Прежде чем разобраться с основами процедуры кодирования, следует ознакомиться с несколькими простейшими понятиями.
Код – это набор любых символов или других визуальных обозначений информации, который образует представление данных. В компьютерной технике под кодом подразумевают отдельную систему знаков, которые используют для обработки, передачи и хранения сообщений и файлов.Кодирование – это процесс преобразования текстовой информации в код. Кодов существует огромное количество. Каждый из них отличается своим алгоритмом работы и алфавитом.
К примеру, компьютер, смартфон, ноутбук и любые другие компьютерные устройства работают с двоичным кодом.
Двоичный код использует алфавит, который состоит из двух символов – «0» и «1».
Декодирование – это процедура обратная к кодированию. Декодировщик обратно превращает код в понятную для человека форму представления данных. Среди известных примеров постоянной работы с декодированием можно отметить азбуку Морзе: для «прочтения» сообщения нужно сначала преобразовать полученный код в слова.
В компьютерной технике кодирование происходит, когда пользователь вводит любую информацию в систему – создает файлы, печатает текст и так далее.
Для понимания обычных букв кириллицы или латиницы они превращаются в набор нолей и единиц.
Чтобы отобразиться на экране компьютера, система проводит декодирование числовой последовательности и выводит результат на экран.
Все эти действия выполняются за тысячные доли секунды.
к содержанию ↑История развития кодирования
Телеграф Шаппа
Первым техническим средством кодирования данных был созданный в 1792 году телеграф Шаппа.
Устройство передавало оптическую информацию в простейшем виде с помощью специальной таблицы кодов, в которой каждой букве латинского алфавита соответствовала одна фигура.
В результате, телеграф мог отобразить и передать набор фигур.
Скорость передачи таких сообщений составляла всего два слова в минуту.
Технология такого обмена сообщениями была актуальна больше ста лет после создания телеграфа Шаппа.
Телеграф Морзе
Созданный в 1837 году телеграф Морзе стал революционном устройством кодирования/декодирования информации.
Принцип кодирования заключался в преобразовании любого сообщения в три символа алфавита:
- Длинный сигнал – тире;
- Короткий сигнал – точка;
- Нет сигнала – пауза.
Подобная связь используется по сей день в мореходной сфере для мгновенной передачи сообщений между суднами.
Радиоприёмник
В 1899 году А. Попов создал первый в мире беспроводной телеграф или радиоприемник.
Принцип его работы заключался в кодировании электрических сигналов азбукой Морзе и её дальнейшей передаче на длительные расстояния.
Позже был изобретен телеграф Бодо, который решал проблему неравномерности кода и сложность декодирования.
Следующий этап в развитии кодирования – это создание вычислительных машин и их работа с бинарной системой исчисления.
к содержанию ↑Современные способы кодирования данных
Для перевода информации в код могут быть использованы разные способы и алгоритмы кодирования.
Использование каждого из методов зависит от среды, цели и условий создания кода.
С разными алгоритмами кодирования мы сталкиваемся в повседневной жизни:
- Для записи разговорной речи в режиме реального времени используется стенография;
- Для написания и отправки письма жителю другой страны используем язык получателя;
- Для набора русского текста на англоязычной клавиатуре используем транслит. К примеру, «Привет»>«Privet» и так далее.
Двоичное кодирование и другие числовые системы
Самый простой и распространенный способ кодирования – это представление информации в двоичном (бинарном) коде.
С его помощью работают все компьютеры и вычислительные системы.
Компьютер может выполнять сверхбыстрые вычисления с помощью только двух условий – наличия тока и его напряжение.
С помощью единиц передается высокое напряжение, а с помощью нолей – низкое.
Далее полученная последовательность считывается центральным процессором, обрабатывается, а затем снова преобразуется в читаемый нам вид и выводится на экран.
Для перевода привычных нам слов, цифр и символов в десятичное представление следует использовать специальные таблицы конверсии.
На рисунке ниже изображена таблица для цифровой и символьной раскладки, а также для букв латиницы.
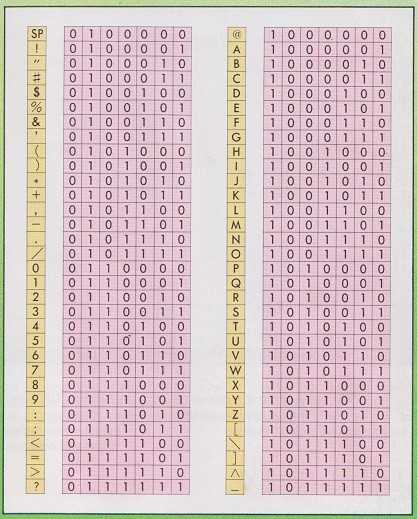
К примеру, в результате перевода фразы «Hello, how are you?» получим последовательность «10010001000101100110010011001001111010110001000001001000100111110101110100001000001101001010001010100000101100110011111010101».
Чтобы выполнить декодирование информации, необходимо разделить бинарный код на части, каждая из которых равна семи ячейкам:
- 1001000 – символ «H»
- 1000101 – символ «E»
- 1001100 – символ «L»
- 1001100 – символ «L»
- 1001111 – символ «O»
- 0101100 – символ «,» и так далее, пока вся последовательность не будет декодирована.
Запятые, точки, другие пунктуационные символы и пробел тоже нужно учитывать при кодировании/декодировании информации.
Также, в теории кодирования можно встретить не только двоичную систему, но и троичную, четвертую, пятую, шестую…шестнадцатеричную и другие системы.
Шестнадцатеричная система исчисления используется в языках программирования низкого уровня.
Таким образом, удаётся добиться более быстрого выполнения кода центральным процессором. Примером такого языка является машинный код ассемблер.
Создание программ на языке низкого уровня является самым сложным и непрактичным, поэтому на практике используют компиляторы – утилиты, которые преобразовывают языки высокого уровня в низкий.
Так шестнадцатеричная система декодируется в двоичную.

Рис.3 – пример декодирования зыков программирования разных уровней
Также, шестнадцатеричная система используется в создании программной документации, так намного проще записывать байты.
Для обозначения одного байта требуется только две шестнадцатеричные цифры, а не восемь, как в двоичной системе.
В повседневной жизни мы используем десятичную систему исчисления, алфавит которой представлен в виде чисел от 0 до 9.
Онлайн-кодировщики
Для быстрого преобразования любого текста в набор символов бинарной или других систем исчисления удобнее использовать автоматические кодировщики.
Также, они могут декодировать текст, самостоятельно определяя, какую систему использовал пользователь для кодировки.
Популярным сервисом для создания или расшифровки двоичного кода является DecodeIT .
Ресурс показывает высокую точность преобразования в обе стороны и отличается очень простым пользовательским интерфейсом.
Рис.4 — Сервис DecodeIT
к содержанию ↑Кодирование символов
Кодирование символов – это еще одна важная часть работы любого компьютерного устройства. От вышеописанных числовых систем она отличается тем, что кодирование происходит уже на этапе работы программы с определенным текстом, сообщением и другим видом данных.
Для кодирования символов используются различные стандарты, среди которых Юникод, ASCII, UTF-8 и другие.
Зачем нужна кодировка символов?
Любые символы на экране компьютера или смартфона отображаются за счет двух вещей:
1 Векторного представления;
2 Предустановленных знаков и их кода.
Знаки – это шрифты, которые поддерживаются устройством. В ОС Windows они находятся в окне Панель управления (директория «Шрифты»).
С помощью этой папки вы можете добавлять или удалять существующие представления символов.
С помощью программного кода выбирается нужное векторное направление символа и его изображение из папки «Шрифты».
Таким образом, на экране появляется буква и текст.
За установку шрифтов отвечает операционная система вашего компьютера, а за кодировку текста – программы, в которых вы набираете или просматриваете текстовые данные.
Любая программа, к примеру стандартный Блокнот, в процессе открытия считывает кодировку каждого знака, производит декодирование данных и выводит информацию для просмотра или дальнейшего редактирования пользователем.
Разбирая код, приложение обрабатывает кодировку знака и ищет его соответствие в поддерживаемом для этого же документа шрифте.
Если соответствие не найдено, вместо текста вы увидите набор непонятных символов.
Рис.5 – пример ошибки кодирования символов в Блокноте Windows
Чтобы символы кириллицы и латиницы открывались без проблем в большинстве программ, было предложено ввести стандарты кодирования.
Один из наиболее популярных – это Юникод (или Unicode).
Он поддерживается практически всеми существующими шрифтами и программным обеспечением.
Также, широко используются технологии UTF-8, ASCII.
Если в программе текст отображается в нечитабельной форме, пользователь может самостоятельно его декодировать.
Для этого достаточно зайти в настройки текстового редактора и сохранить файл с кодировкой Юникод или другими популярными форматами кодирования.
Затем откройте файл заново, текст должен отображаться в нормальном режиме.
Рис.6 – декодирование текста в редакторе
к содержанию ↑Шифрование
Часто возникает необходимость не только закодировать информацию, но и скрыть её содержимое от посторонних.
Для таких целей используется шифрование.
Простыми словами, шифрование – это кодирование информации, но не с целью её корректного представления на экране компьютера, а с целью сокрытия данных от тех, кому не положено получать доступ к шифрованной информации.
Алфавит шифрования состоит из двух элементов:
Алгоритм – уникальная последовательность математических действий с двоичными числами;
Ключ – бинарная последовательность, которая добавляется к шифруемому сообщению.
Дешифрование – это обратный процесс к защитному кодированию, который подразумевает превращение данных в первоначальный вид с помощью известного ключа.
Криптография – это наука о шифровании данных. Всего различают два раздела криптографии:
- Симметричная – в таких криптосистемах кодирования для шифрования и дешифрования используют один и тот же ключ. Недостаток системы – низкая стойкость ко взлому;
- Ассиметричная – для шифрования используются закрытый и открытый ключ. Таким образом, посторонний человек не сможет расшифровать (декодировать) сообщение, даже если алгоритм известен.
Где используется криптография?
Кодирование информации с целью шифрования используется уже более трех тысяч лет.
Истории известны первые попытки шифрованной передачи сообщений между известными полководцами царями и просто высокопоставленными людьми.
Сегодня без криптографии невозможно существование всей банковской системы, ведь каждая карта, каждая авторизация в онлайн-банкинге требует наличия защищенного соединения, при котором злоумышленник не сможет похитить ваши деньги или подобрать пароль.
Также, шифрованное кодирование используется в обычных социальных сетях, мессенджерах.
К примеру, Telegram – мессенджер, главной особенностью которого является кодирование сообщений пользователей таким образом, чтобы никто посторонний не смог взломать переписку.
Также, алгоритмы шифрования встроены во все операционные системы, облачные хранилища.
Они нужны для защиты ваших личных данных.
Рис.7 – принцип работы защищенного соединения
к содержанию ↑Стеганография
Стеганография – это еще один способ кодирования информации.
Он схож с упомянутой выше криптографией, но если основной целью криптографии является защита секретной информации, то стеганография отвечает за сокрытие самого факта о том, что существуют какие-либо защищаемые данные.
Процедура стенографического кодирования подразумевает встраивание сообщения в картинки, музыкальные файлы, видео и так далее.
Алфавитом такого кодирования является область пикселей изображения.
Каждая буква секретного сообщения кодируется в бинарную форму, затем она заменяет один из пикселей.
Таким образом, можно закодировать даже большие сообщения без какого-либо визуального изменения фотографии, так как на современных гаджетах не видны отдельные пиксели картинки.
Аналогичным образом происходит кодирование звука в музыку, каждой частоте присваивается определенная буква.
Декодировать стенографическую информацию можно только с помощью специальных утилит, которые и зашифровали сообщение или путем взлома.
Достаточно сопоставить картинку до и после встраивания секретного текста, количество пикселей будет отличаться.
Затем используется специальное ПО для перебора и расшифровки каждого пикселя и воссоздания сообщения.
к содержанию ↑Итог
Кодирование информации используется сотни лет для удобной передачи данных между устройствами.
С развитием технологий и переносом банковской сферы в техническую среду появилась необходимость в использовании алгоритмов кодирования, которые бы шифровали информацию, сохраняя её от несанкционированного доступа.
Сегодня без технологий кодирования данных невозможна работа ни одного компьютера, смартфона, сайта или банковского счета.
Тематические видеоролики:
Каталог программ
geek-nose.com
Сжатие способом кодирования серий
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем — это кодирование серий последовательностей (Run Length Encoding — RLE). Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений. Проблема всех аналогичных методов заключается лишь в определении способа, при помощи которого распаковывающий алгоритм мог бы отличить в результирующем потоке байтов кодированную серию от других — некодированных последовательностей байтов. Решение проблемы достигается обычно простановкой меток в начале кодированных цепочек. Такими метками могут быть, например, характерные значения битов в первом байте кодированной серии, значения первого байта кодированной серии и т.п. Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF:), т.к. последние содержат достаточно много длинных серий повторяющихся последовательностей байтов. Недостатком метода RLE является достаточно низкая степень сжатия или стоимость кодирования файлов с малым числом серий и, что еще хуже — с малым числом повторяющихся байтов в сериях.
Сжатие без применения метода rle
Процесс сжатия данных без применения метода RLE можно разбить на два этапа: моделирование (modelling) и, собственно, кодирование (encoding). Эти процессы и их реализующие алгоритмы достаточно независимы и разноплановы.
Процесс кодирования и его методы
Под кодированием обычно понимают обработку потока символов (в нашем случае байтов или полубайтов) в некотором алфавите, причем частоты появления символов в потоке различны. Целью кодирования является преобразование этого потока в поток бит минимальной длины, что достигается уменьшением энтропии входного потока путем учета частот символов. Длина кода, представляющего символы из алфавита потока должна быть пропорциональна объему информации входного потока, а длина символов потока в битах может быть не кратна 8 и даже переменной. Если распределение вероятностей частот появления символов из алфавита входного потока известно, то можно построить модель оптимального кодирования. Однако, ввиду существования огромного числа различных форматов файлов задача значительно усложняется т.к. распределение частот символов данных заранее неизвестно. В таком случае, в общем виде, используются два подхода.
Первый заключается в просмотре входного потока и построении кодирования на основании собранной статистики (при этом требуется два прохода по файлу — один для просмотра и сбора статистической информации, второй — для кодирования, что несколько ограничивает сферу применения таких алгоритмов, т.к., таким образом, исключается возможность однопроходного кодирования «на лету», применяемого в телекоммуникационных системах, где и объем данных, подчас, не известен, а их повторная передача или разбор может занять неоправданно много времени). В таком случае, в выходной поток записывается статистическая схема использованного кодирования. Данный метод известен как статическое кодирование Хаффмена [Huffman].
Второй метод — метод адаптивного кодирования (adaptive coder method). Его общий принцип состоит в том, чтобы менять схему кодирования в зависимости от характера изменений входного потока. Такой подход имеет однопроходный алгоритм и не требует сохранения информации об использованном кодировании в явном виде. Адаптивное кодирование может дать большую степень сжатия, по сравнению со статическим, поскольку более полно учитываются изменения частот входного потока. Данный метод известен как динамическое кодирование Хаффмана [Huffman], [Gallager], [Knuth], [Vitter].
В статическом кодировании Хаффмана входным символам (цепочкам битов различной длины) ставятся в соответствие цепочки битов, также, переменной длины — их коды. Длина кода каждого символа берется пропорциональной двоичному логарифму его частоты, взятому с обратным знаком. А общий набор всех встретившихся различных символов составляет алфавит потока. Это кодирование является префиксным, что позволяет легко его декодировать результативный поток, т.к., при префиксном кодировании, код любого символа не является префиксом кода никакого другого символа — алфавит уникален.
Пример:
Пусть входной алфавит состоит из четырех символов: a, b, c, d, частоты которых в входном потоке равны, соответственно, 1/2, 1/4, 1/8, 1/8. Кодирование Хаффмана для этого алфавита задается следующей таблицей:
Например, кодом цепочки abaaacb, представленной на входе как 00 01 00 00 00 10 01, будет 0 10 0 0 0 110 10, соответственно — 14 бит на входе дали 11 бит на выходе. Кодирование по Хаффману обычно строится и хранится в виде двоичного дерева, в «листьях» которого находятся символы, а на «ветвях» — цифры 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 «собираются» в одну уникальную последовательность.
При использовании адаптивного кодирования Хаффмана усложнение алгоритма состоит в необходимости постоянной корректировки дерева и кодов символов основного алфавита в соответствии с изменяющейся статистикой входного потока.
Методы Хаффмана дают достаточно высокую скорость и умеренно хорошее качество сжатия. Эти алгоритмы давно известны и широко применяется как в программных (всевозможные компрессоры, архиваторы и программы резервного копирования файлов и дисков), так и в аппаратных (системы сжатия «прошитые» в модемы и факсы, сканеры) реализациях.
Однако, кодирование Хаффмана имеет минимальную избыточность при условии, что каждый символ кодируется в алфавите кода символа отдельной цепочкой из двух бит — {0, 1}. Основным же недостатком данного метода является зависимость степени сжатия от близости вероятностей символов к 2 в некоторой отрицательной степени, что связано с тем, что каждый символ кодируется целым числом бит. Так при кодировании потока с двухсимвольным алфавитом сжатие всегда отсутствует, т.к. несмотря на различные вероятности появления символов во входном потоке алгоритм фактически сводит их до 1/2.
Данная проблема, как правило, решается путем введения в алфавит входного потока новых символов вида «ab», «abc»,. . . и т.п., где a, b, c — символы первичного исходного алфавита. Такой процесс называется сегментацией или блокировкой входного потока. Однако, сегментация не позволяет полностью избавиться от потерь в сжатии (они лишь уменьшаются пропорционально размеру блока), но приводит к резкому росту размеров дерева кодирования, и, соответственно, длине кода символов вторичных алфавитов. Так, если, например, символами входного алфавита являются байты со значениями от 0 до 255, то при блокировании по два символа мы получаем 65536 символов (различных комбинаций) и столько же листьев дерева кодирования, а при блокировании по три — 16777216! Конечно, при таком усложнении, соответственно возрастут требования и к памяти и ко времени построения дерева, а при адаптивном кодировании — и ко времени обновления дерева, что приведет к резкому увеличению времени сжатия. Напротив, в среднем, потери составят 1/2 бита на символ при отсутствии сегментации, и 1/4 или 1/6 бита соответственно при ее наличии, для блоков длиной 2 и 3 бита.
studfiles.net
Глава 8. Основы теории кодирования
8.1. ЗАДАЧИ КОДИРОВАНИЯ. КЛАССИФИКАЦИЯ МЕТОДОВ КОДИРОВАНИЯ
Ранее указывалось, что источник сообщения включает кодирующую систему, формирующую сигналы по известным получателю правилам. Ввиду независимости содержания сообщения от выбранной формы его представления, возможно преобразование одного кода в другой, предоставив правило обратного преобразования получателю сообщения.
Целесообразность такого дополнительного кодирования сообщения на передающей стороне и соответствующего декодирования на приемной стороне возникает из-за избыточности алфавита сообщения и искажения сигналов действующими в канале связи помехами.
Кодирование предшествует хранению и передаче информации. Реализация основных характеристик канала связи помимо разработки технических устройств, требует решения информационных задач – выбор оптимального метода кодирования.
Основными задачами кодирования являются:
согласование источника с каналом по объемам алфавитов;
повышение скорости передачи информации по каналу за счет устранения избыточности в последовательности сигналов, подаваемых на его вход;
повышение помехоустойчивости передачи информации введением, определенным образом, избыточности в последовательность сигналов.
Первые две задачи направлены на преобразование последовательности сигналов, поступающей от источника сообщений на вход канала. Это, так называемая, задача кодирования источника. Кодер, осуществляющий кодирование источника сообщений включается, как правило, в состав оконечной аппаратуры. Третья задача обычно решается кодированием, реализуемым в самом канале. Это задача помехоустойчивого кодирования.
Кодирование источника и помехоустойчивое кодирование – это две самостоятельные задачи. Их раздельное теоретическое и практическое решение обусловлено различием свойств источников, использующих данный канал связи. Необходимо иметь ввиду, что кодирование, обеспечивающее изменение структуры сигналов, ни в какой мере не должно изменять количество информации, заключенной в первоначальном сообщении.
Под кодированием в широком смысле, понимают отображение сообщения в сигнал для передачи его по каналу.
Под кодированием в узком смысле понимают преобразование сообщений дискретного источника для передачи их по дискретному каналу. Если иное не указано, под словом «кодирование» далее будет подразумеваться кодирование в узком смысле.
Рассмотрим модель системы передачи (и хранения) информации, приведенной на рис. 8.1. Нужно отметить, что на самом деле проблемы, возникающие при передаче и хранении информации (на оптических дисках, магнитных носителях и в памяти компьютеров) очень схожи, поэтому методы их решения и структура технических устройств также во многом идентичны.
Рис. 8.1 Модель системы передачи (и хранения) информации
Реализация кодирования на передающей стороне всегда предполагает применение обратной процедуры — декодирования — для восстановления принятого сообщения. Устройства, осуществляющие кодирование и декодирование, называются соответственно кодер и декодер. Вместе их называют кодеком.
Под кодированием в общем случае понимают преобразование
алфавита сообщения 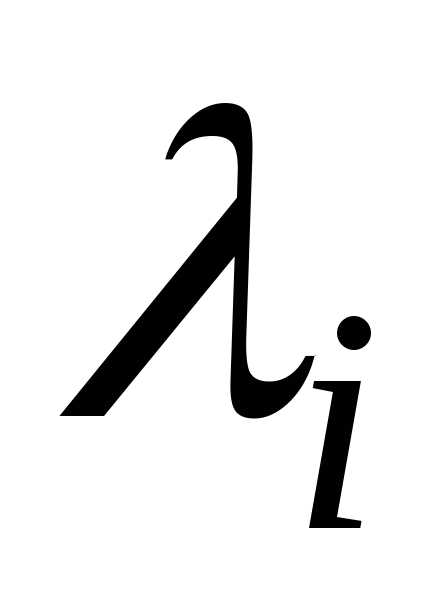 ,в алфавит некоторым образом выбранных
кодовых символов
,в алфавит некоторым образом выбранных
кодовых символов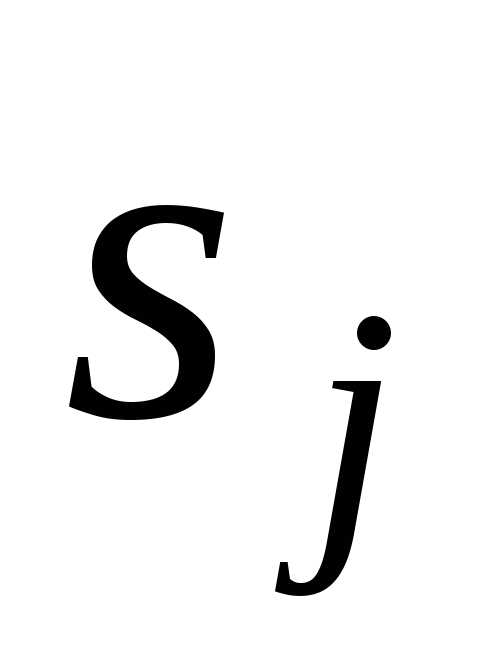 . Обычно (но
не обязательно) размер алфавита кодовых
символов dim {
. Обычно (но
не обязательно) размер алфавита кодовых
символов dim { 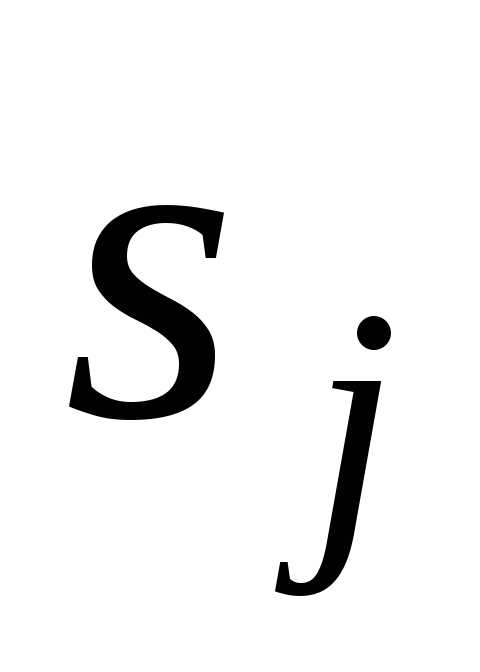 } меньше или намного меньше размера
алфавита источника dim{λi}. Кодирование сообщений может преследовать
различные цели — сокращение объема
передаваемых данных (сжатие данных),
увеличение количества передаваемой за
единицу времени информации, повышение
верности передачи, обеспечение секретности
при передаче и т.д.
} меньше или намного меньше размера
алфавита источника dim{λi}. Кодирование сообщений может преследовать
различные цели — сокращение объема
передаваемых данных (сжатие данных),
увеличение количества передаваемой за
единицу времени информации, повышение
верности передачи, обеспечение секретности
при передаче и т.д.
Кодер источника. Подавляющая часть исходных сообщений — речь, музыка, изображения и т.д. — предназначена для непосредственного восприятия органами чувств человека и в общем случае плохо приспособлена для их эффективной передачи по каналам связи. Поэтому сообщения (λ(t) или Λ), как правило, подвергаются кодированию. В процедуру кодирования обычно включают и дискретизацию непрерывного сообщения λ(t), то есть его преобразование в последовательность элементарных дискретных сообщений { λi }.
Под кодированием источника будем понимать сокращение объема (сжатие) информации с целью повышения скорости ее передачи или сокращения полосы частот, требуемых для передачи.
Кодирование источника иногда называют экономным, безызбыточным или эффективным кодированием, а также сжатием данных. Под эффективностью в данном случае понимается степень сокращения объема данных, обеспечиваемая кодированием.
Кодер канала. При передаче информации по каналу связи с помехами в принятых данных могут возникать ошибки. Если такие ошибки имеют небольшую величину или возникают достаточно редко, информация может быть использована потребителем. При большом числе ошибок полученной информацией пользоваться нельзя.
Кодирование в канале, или помехоустойчивое кодирование, представляет собой способ обработки передаваемых данных, обеспечивающий уменьшение количества ошибок, возникающих в процессе передачи по каналу с помехами. Существует большое число различных методов помехоустойчивого кодирования информации, но все они основаны на следующем: при помехоустойчивом кодировании в передаваемые сообщения вносится специальным образом организованная избыточность (в передаваемые кодовые последовательности добавляются избыточные символы), позволяющая на приемной стороне обнаруживать и исправлять возникающие ошибки. Таким образом, если при кодировании источника производится устранение естественной избыточности, имеющей место в сообщении, то при кодировании в канале избыточность в передаваемое сообщение сознательно вносится. На выходе кодера канала в результате формируется последовательность кодовых символов X, называемая кодовой последовательностью.
Нужно отметить, что как помехоустойчивое кодирование, так и сжатие данных не являются обязательными операциями при передаче информации. Эти процедуры (и соответствующие им блоки в структурной схеме) могут отсутствовать. Однако это может привести к очень существенным потерям в помехоустойчивости системы, значительному уменьшению скорости передачи и снижению качества передачи информации. Поэтому практически все современные системы (за исключением, быть может, самых простых) должны включать и обязательно включают и эффективное и помехоустойчивое кодирование данных.
Классификация рассматриваемых методов кодирования приведена на рис. 8.2. Эта классификация не является, исчерпывающей. В нее включены лишь некоторые методы, которые широко используются в современных системах связи. По своему назначению кодирование подразделяется на примитивное, экономное и помехоустойчивое.
Примитивное, или безызбыточное, кодирование применяется для согласования алфавита источника и алфавита канала.
Пример, приведённый
в таблице 8.1, показывает, как сообщения
дискретного источника с объёмом алфавита 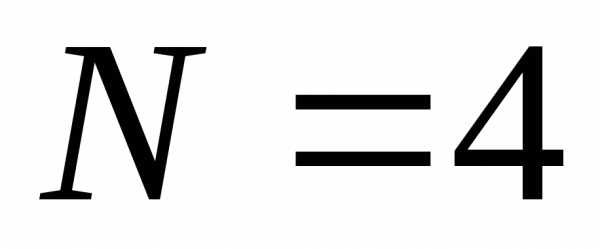 могут быть преобразованы для передачи
по дискретному двоичному каналу.
Отличительное свойство примитивного
кодирования состоит в том, что
избыточность дискретного источника,
образованного выходом примитивного
кодера, равна избыточности источника
на входе кодера.
могут быть преобразованы для передачи
по дискретному двоичному каналу.
Отличительное свойство примитивного
кодирования состоит в том, что
избыточность дискретного источника,
образованного выходом примитивного
кодера, равна избыточности источника
на входе кодера.
Таблица 8.1. Пример примитивного кодирования
Сообщения дискретного источника | Выход кодера |
а0 | 00 |
а1 | 01 |
а2 | 10 |
а3 | 11 |
Экономное кодирование, или сжатие данных, применяется для уменьшения времени передачи информации или требуемого объема памяти при её хранении. Отличительное свойство экономного кодирования состоит в том, что избыточность источника, образованного выходом кодера, меньше, чем избыточность источника на входе кодера. Экономное кодирование применяется в ЭВМ. Так, версии операционных систем обязательно содержат в своём составе программы сжатия данных (динамические компрессоры и архиваторы), а стандарты нa модемы включает сжатие в число процедур обработки данных.
Если сжатие производится так, что по сжатым данным можно абсолютно точно восстановить исходную информацию, кодирование называется неразрушающим. Неразрушающее кодирование используется при передаче (или хранении) текстовой информации, числовых данных, компьютерных файлов и т.п., то есть там, где недопустимы даже малейшие отличия исходных и восстановленных данных.
Во многих случаях нет необходимости в абсолютно точной передаче информации от источника к ее потребителю, тем более что в канале связи всегда присутствуют помехи и абсолютно точная передача в принципе невозможна. В таких случаях может быть использовано разрушающее сжатие, обеспечивающее восстановление исходного сообщения по сжатому, с той или иной степенью приближения. Как правило, разрушающие методы сжатия гораздо более эффективны, нежели неразрушающие.
Таким образом, на
выходе кодера источника по передаваемому
сообщению λ(t)
или Λ формируется
последовательность кодовых символов  ,
называемая информационной
последовательностью, допускающая
абсолютно точное (или приближенное)
восстановление исходного сообщения и
имеющая, по возможности, как можно
меньший размер.
,
называемая информационной
последовательностью, допускающая
абсолютно точное (или приближенное)
восстановление исходного сообщения и
имеющая, по возможности, как можно
меньший размер.
Помехоустойчивое, или избыточное, кодирование применяется для обнаружения и (или) исправления ошибок, возникающих при передаче по дискретному каналу. Отличительное свойство помехоустойчивого кодирования состоит в том, что избыточность источника, образованного выходом кодера, больше, чем избыточность источника на входе кодера. Помехоустойчивое кодирование используется в различных системах связи, при хранении и передаче данных в сетях ЭВМ, в бытовой и профессиональной аудио- и видеотехнике, основанной на цифровой записи.
studfiles.net